¿Qué es el Topic Modelling?
El Topic Modelling es una técnica de Aprendizaje Automático, concretamente de la rama de Procesamiento del Lenguaje Natural, que intenta asignar temas (topics) a un conjunto de textos. Estos modelos se basan en la búsqueda de posibles relaciones entre las palabras que aparecen en los distintos textos. Aquellas palabras que estén relacionadas entre sí formarán un conjunto (cluster) que llamaremos topic y trataremos de que sea lo más diferente posible al resto de topics.
Estos modelos son útiles para identificar temáticas en un conjunto de documentos y así poder clasificarlos en función de estos topics o tener una idea más clara sobre de qué se está hablando en una determinada fuente de datos, en este caso la red social Reddit.
Existen varios algoritmos de Topic Modelling disponibles implementados en diferentes bibliotecas y lenguajes. En este caso se ha utilizado el algoritmo LDA (Latent Dirichlet Allocation) disponible en la biblioteca Gensim para Python.
Preprocesado de los datos y entrenamiento del modelo
Los distintos textos con los que vamos a entrenar el modelo se han extraído de Reddit. Concretamente, se han recogido datos de los subreddits r/uber y r/uberdrivers con el objetivo de observar de qué temas hablan tanto los usuarios de ride-hailing como sus conductores. En este caso, para entrenar el modelo se dispone de un conjunto de casi 1.200.000 textos divididos en posts, títulos de los posts y comentarios. Es importante destacar que, cuantos más textos se tenga, más eficiente será el resultado del entrenamiento.
Antes de entrenar el LDA, es necesario realizar una limpieza y preprocesado exhaustivos de los textos para evitar entrenar el modelo con términos que no añadan significado o estropeen los datos. Es decir, el objetivo será identificar el máximo número de topics empleando el mínimo número de palabras posibles. El preprocesado que se ha realizado de los textos para obtener el modelo final se muestra en la siguiente imagen:
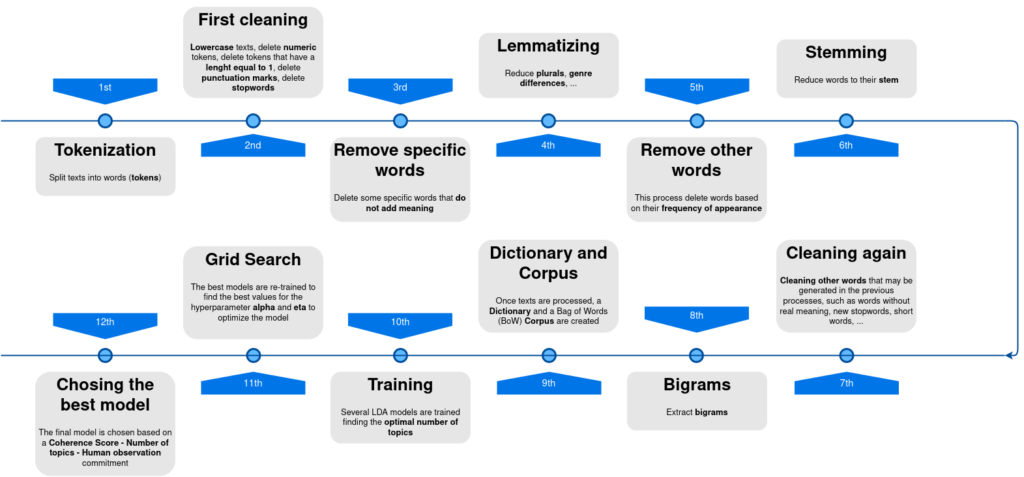
Las distintas fases de preprocesado de los textos se han ido ajustando durante el entrenamiento de los modelos, analizando si efectivamente mejoraban o no el modelo. Por ello, algunos modelos eliminan palabras que no se eliminan en otros modelos o realizan procesos diferentes a otros. Por ejemplo, algunos modelos se han entrenado sin haber aplicado previamente el proceso de «stemming» o con criterios distintos a la hora de formar bigramas. El modelo que finalmente se ha utilizado ha sido entrenado con textos que han seguido el preprocesado mostrado en la imagen anterior.
Una vez se tienen los distintos documentos procesados, se crea un diccionario que contiene las palabras que aparecen en los textos y posteriormente se emplea este diccionario para crear un corpus que estará formado por los textos en formato Bag of Words (cada palabra se representa con una tupla compuesta por un número que identifica la palabra y el número de veces que aparece en el texto).
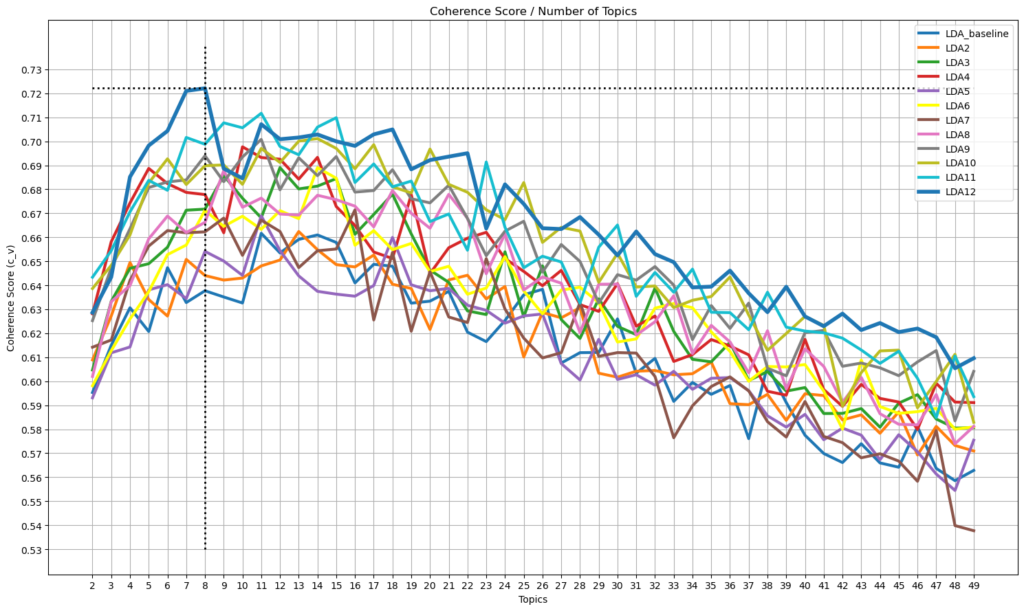
Una vez tenemos los documentos representados de esta manera, entrenamos el modelo. El LDA necesita que se le indique el número de topics que tiene que intentar encontrar en los documentos. Para optimizar la búsqueda de los topics, se ha entrenado cada modelo buscando desde 2 hasta 50 topics. Para ver en un primer momento cuál es el mejor modelo y cuál es el número de topics óptimo, se han analizado dos métricas que nos dan una idea de cómo son los modelos: la Métrica de Coherencia y la Perplejidad.
La Métrica de Coherencia nos da una idea de cómo de coherente es un modelo en cuanto a la distribución de sus topics: cuanto más distintas sean las palabras de los topics entre sí, menos relacionados estarán los topics y más coherente será el modelo. Por otro lado, la Perplejidad es una medida de cuánto se sorprende el modelo cuando se le añade datos que no había visto antes.
El análisis de los modelos, aunque se han utilizado ambas métricas, se ha basado principalmente en el análisis de la coherencia. En la figura siguiente se muestra la variación de la coherencia en función del número de topics y de los distintos modelos entrenados. Cabe destacar que el mejor modelo que se ha obtenido ha sido el LDA12 y que se partió en un primer momento del LDA_baseline. Por tanto, gracias a las diferencias en el preprocesado de los textos que se ha comentado antes, se ha conseguido mejorar considerablemente la coherencia del modelo.
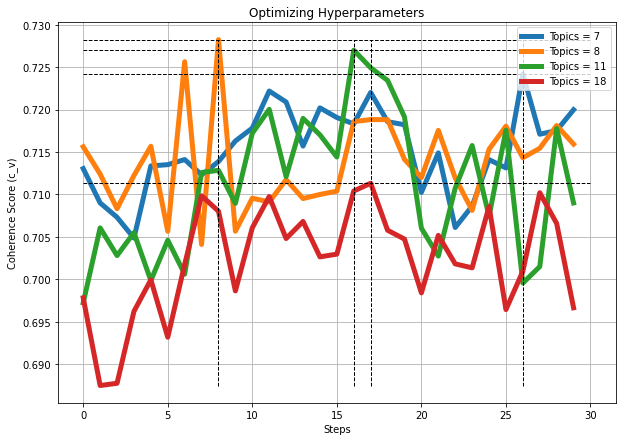
Una vez se tiene el mejor modelo y en un intento de mejorarlo aún más, se ha realizado una búsqueda de los hiperparámetros (alpha y eta) óptimos para el modelo. Para ello, se han empleado los cuatro modelos con mayor coherencia utilizando el preprocesado del LDA12, que son aquellos que tienen 7, 8, 11 y 18 topics. El resultado de la búsqueda del valor de alpha y eta y la coherencia de los modelos para esos valores se muestra a continuación:
Elección del mejor modelo
Los resultados de los modelos en cuanto a su coherencia son, al menos en los modelos con 7, 8 y 11 topics, similares y todos ellos con coherencias máximas cercanas al 73%. El modelo elegido, además de ser coherente, deberá ser entendible para el ser humano y disponer del mayor número de topics que representen claramente una temática diferenciada del resto de los topics. Por ello, la elección del mejor modelo se ha basado en un compromiso Coherencia – Número de topics – Observación humana. En función de este análisis, el modelo elegido fue el compuesto por 11 topics, con una coherencia de 72.70% para un alpha = 0.91 y eta = 0.31. Para elegir específicamente este modelo, lo primero que se ha hecho es observar la distribución de los topics en el plano y la separación entre ellos, para lo que se ha utilizado la herramienta pyLDAvis. La aplicación de esta herramienta al modelo elegido se muestra a continuación:
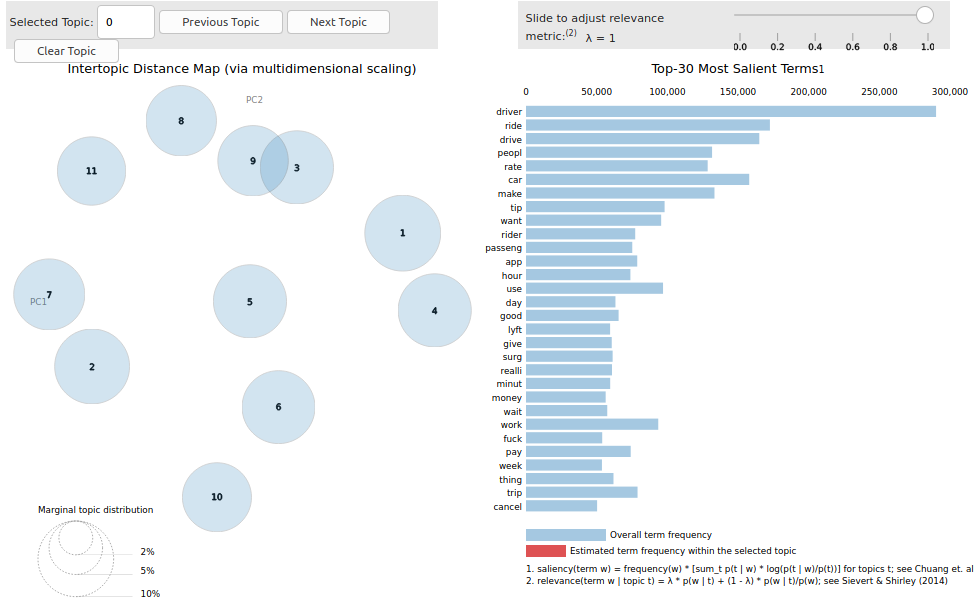
Se puede apreciar en la imagen que todos los topics son independientes entre sí excepto los que pyLDAvis identifica como topic 9 y 3. Por lo tanto, podemos decir a priori que este es un buen modelo, ya que la separación entre los distintos topics es grande y casi todos ellos están poco o nada relacionados.
Por otro lado, es conveniente saber que el LDA devuelve para cada topic un conjunto de palabras con unos pesos asociados que identifican dicho topic. Esto quiere decir que no provee de un nombre para cada topic. Por eso, una tarea fundamental en ver si un modelo es bueno o no es que sea identificable para un ser humano. Para ello hemos obtenido las palabras que según el modelo tienen más peso en ese topic. Además, para evitar la confusión de dichos topics e identificarlos mejor, se extrajeron una serie de palabras clave para cada uno de ellos. El criterio para elegir estas palabras clave fue el siguiente:
- Asignar a cada texto un topic.
- Extraer las 100 palabras más comunes que aparecen en los textos para cada uno de los topics.
- Ver cuáles eran las palabras dentro de ese grupo de palabras que solo aparecían en los textos etiquetados con cada uno de los topics.
Observando estos dos grupos de palabras para cada topic, se han identificado y nombrado los topics de la siguiente manera. Se muestran también algunas palabras representativas de estos topics:
- Topic 0: Conversations inside the car – Travelling: «talk», «accept», «request», «ride», «pool», «music», «conversation».
- Topic 1: Vehicles – People: «car», «seat», «clean», «water», «door», «man», «girl».
- Topic 2: Ubereats – Ordering food: «ubereats», «restaurant», «food», «cash», «delivery», «order», «eat».
- Topic 3: Time related – Differences in the time of day: «hour», «day», «morning», «weekend», «drove», «today», «start».
- Topic 4: Prices – Different ridesharing services: «lyft», «market», «taxi», «price», «fare», «uberx», «cab».
- Topic 5: Travelling – Cancelations and requests – Taking an Uber: «cancel», «trip», «traffic», «waiting», «destination», «pickup», «location».
- Topic 6: Reddit related: «post», «lol», «shit», «troll», «sub», «comment», «idiot».
- Topic 7: Job conditions: «money», «tax», «gas», «maintenance», «income», «wage», «mileage».
- Topic 8: Legal Coverage: «insurance», «state», «law», «employee», «legal», «claim», «worker».
- Topic 9: Drivers’ Rating: «driver», «rate», «star», «experience», «reason», «system», «matter».
- Topic 10: Application – Communications – Support: «app», «phone», «support», «report», «account», «information», update».
Conclusiones
Gracias a las técnicas de Topic Modelling y un procesado de textos exigente, conocemos de qué temáticas se está hablando en la red social Reddit sobre ride-hailing. Con estos datos, podremos analizar a partir de ahora la manera en la que hablan de cada uno de estos topics e identificar así distintos tipos de opinión o diferentes motivos de quejas por parte de usuarios y conductores.